input space -> use linear decision boundaries -> labeled regions
Ex) 1~K의 클래스가 존재한다.
k번째 클래스를 분류하는 변수, 함수가 fk(x) 라면 fk(x)=bk0+bk^Tx이다.
k, l번째 클래스 사이에서 분리 -> fk(x)=fl(x), (bk0-bl0) + (bk-bl)^T x=0 의 affine set, hyperplane이 존재해야 한다.
=> 이를 위해, x를 특정 클래스로 분류하기 위해서 discriminant function, dk(x) 함수를 이용한다.
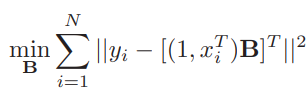
위의 식은 x 열벡터와 y 열벡터 사이에서 최적의 계수 행렬인 B를 적합하기 위한 식이다. y_true-y_pred의 제곱의 합이 최소가 되게 하는 B를 찾는 것이므로 MSE를 사용했다.
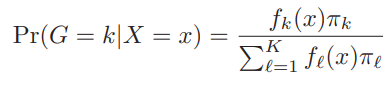
pi: prior distribution, Pr(G=k | X=x)1~K 클래스로 분류할 전체 확률 중 k번 클래스로 분류할 확률
Types of linear classification models:
1. Linear Discriminant Analysis (LDA) -> QDA, RDA
2. Logistic Regression
3. Rosenblatt's perceptron algorithm
4. Optimal separating hyperplane
1. Linear, Quadratic Discriminant Analysis
LDA, QDA -> each class density follows multivariate Gaussian density

1) LDA -> all class k has same covariance matrix sigma

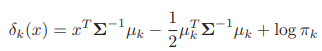

-> k where the value of linear discriminant function d_k(x) is maximized
-> that k is group of x
2) QDA -> each class k has different cov matrix sigma_k
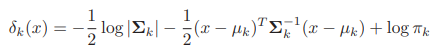
decision boundary between class k and l -> d_k(x)=d_l(x)
3) RDA -> compromise between LDA and QDA, in terms of covariance matrix
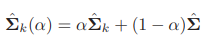
keeping balance between cov of each class, and common cov
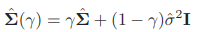
By modifying common cov with identity matrix -> shrink to scalar cov
4) Reduced Rank LDA -> implement LDA using few components and within/between class cov
p-dim input space, K centroids -> dim of affine subspace <= K-1 (Ex: 3 centroids -> project x points to 2D space)
M: class centroids
W: common covariance matrix (within class cov)
-> eigen. decom. of W -> M*=M W^(-1/2) (=> var=1)
-> B*=cov matrix of M*
-> B*=V*DV*^T -> column v_l* -> v_l=W^(-1/2) v_l*
->Z_l=v_l^T X
=> Fisher => find linear combination Z=a^T X where between class cov is maximized and within class cov is minimized

Find a where a^T B a is maximized! (a is discriminant coordinates)
find optimal a, v_l from columns of V*
2. Implementation
1) LDA
Eigenvalue decomposition -> Sigma=UDU^T

Use U, D -> scatter each x point onto the sphere space -> classify the points by finding their closest class centroids.
2) QDA

Conduct eigenvalue decomposition for each class cov, Sigma_k -> get U_k, D_k, mu_k
'머신러닝' 카테고리의 다른 글
| Genetic Algorithm (0) | 2026.02.21 |
|---|---|
| kNN, k means clustering, a priori method (0) | 2026.02.21 |
| EM algorithm (0) | 2026.01.20 |
| Bootstrap in machine learning (0) | 2026.01.19 |
| Chapter 4. Parametric methods (0) | 2025.11.02 |