[The Elements of Statistical Learning]
1. Mixture model: describe the data using mix of multiple simple models (ex: gaussian model)
Ex) two-component mixture model
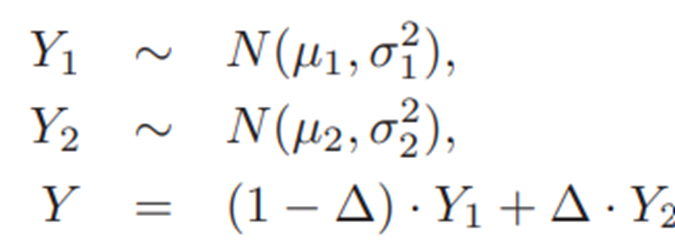
Y: combination of two gaussian models
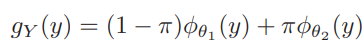
g(y): density of Y
-> sum the log g(y) of N data points -> maximize this log-likelihood
Parameters of the model: pi, mu1, s1, mu2, s2
=> mixture models -> useful for supervised learning, lead to radial basis functions
2. EM algorithm
1) Expectation step: current parameters -> calculate responsibility r_n,k (responsibility of kth model for predicting nth datapoint)
2) Maximization step: use reponsibilities + parameters -> calculate maximum likelihood fits -> update parameters
At the point of weighted means and variances
*initial state: take two of y in random -> initial value of mu1, mu2, sig1, sig2
=> update mu, sigma, pi for multiple iterations until the likelihood get maximized.
3) GEM (making this alg easier): use latent(unobserved) data to enlarge the sample (data augmentation)
E step: observed data Z, theta hat -> Q=E[ l(theta',T) ]
M step: get new estimate theta as maximizer of Q
-> iterate until it Q converges

L calculated with total data T - L calculated with latent data Zm -> maximize this likelihood
'머신러닝' 카테고리의 다른 글
| kNN, k means clustering, a priori method (0) | 2026.02.21 |
|---|---|
| Linear methods for classification - LDA, QDA, RDA (0) | 2026.02.02 |
| Bootstrap in machine learning (0) | 2026.01.19 |
| Chapter 4. Parametric methods (0) | 2025.11.02 |
| Chapter 9. Decision Trees (0) | 2025.11.01 |