1. DNN(Deep Neural Network)의 의미
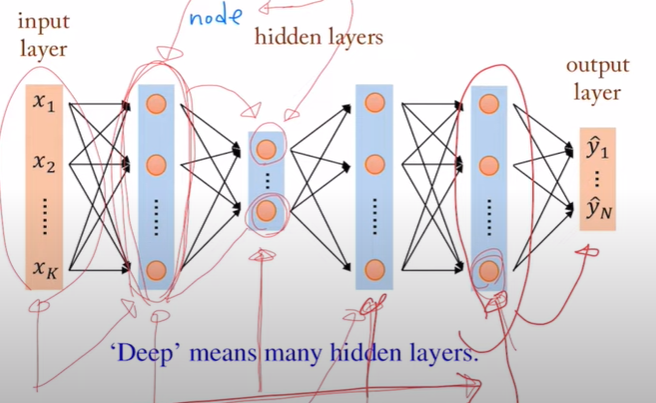
hidden layer를 많이 가지고 있는 neural network이다.
-hidden layer의 수가 많을수록 network가 deep한 것이고, layer의 수가 많으며 layer를 구성하는 node의 수도 많다면 network가 더 복잡해서 정교하게 예측할 수 있다.
-layer를 여러 개 거쳐감에 따라, node의 feature들이 더 정확한 정보를 가지게 된다.
-node수가 같을 때 shallow neural network보다는 layer의 수가 많은 deep neural network가 더 정확한 예측을 할 수 있다.
(layer의 수가 많아야 input layer의 node들이 더 많은 경로를 거쳐서 output을 산출하므로 더 복잡하게 network를 이룰 수 있다.
2. DNN의 단계적 구성
forward pass computation + backpropagation 두 가지가 반복되어 network 성능 향상
1)Forward pass: input이 들어왔을 때 weight, bias와 연산해 output y hat을 출력한다.
2)Backpropagation: y hat, y 사이의 차이를 계산해 오차를 얻는다.
3. DNN forward pass
첫번째 layer의 두 퍼셉트론이 1,-1의 노드 두 개를 feature로 가진다면, 두 퍼셉트론의 값을 얻을 때 행렬로 표현하면 간단하게 표시할 수 있다.
활성화함수(weight행렬*input 행렬 + bias 행렬) <- layer 하나씩 거칠 때마다 이 연산 수행
1) weight 행렬의 column 수는 input node의 수와 같다. row 수는 output node의 수와 같다. 하나의 행의 요소들이 하나의 퍼셉트론의 weight들이다. (i,j)의 요소는 i번째 퍼셉트론의 j번째 weight값을 의미한다.
2) bias 행렬의 column 수는 항상 1인데, bias는 퍼셉트론 하나당 하나씩 존재하므로 input 노드의 수와 관계없기 때문이다.
row 수는 output 노드의 수, 퍼셉트론의 수와 같다.
3)input행렬은 input노드의 값들을 하나의 column에 배열한 행렬이다.
4)활성화 함수는 연속적이고 미분가능할수록 backpropagation에 유리하므로 좋다. (sigmoid function)
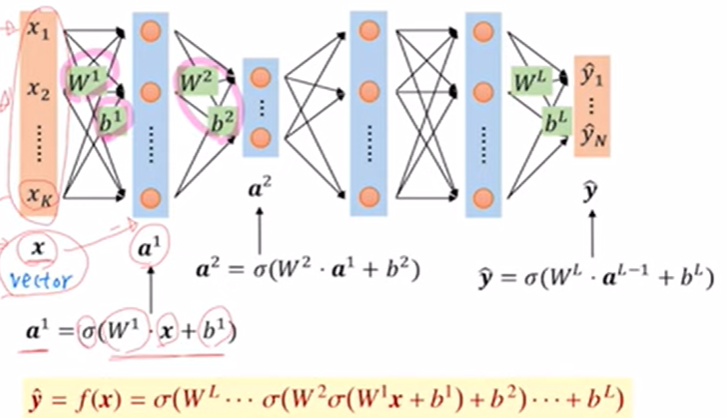
입력벡터가 x이고 hidden layer a1, a2,... 존재한다.
a1=sigma(Wx+b), a2=sigma(Wa1+b) ,...계속 반복하면 최종 output으로 y벡터가 산출된다.
만약 sigma 활성화함수를 각 단계마다 적용하지 않는다면 연산과정이 단순해진다. (y=ax+b꼴이 되어 하나의 layer와 동일해짐)
비선형성을 가지는 활성화함수를 계속 적용하였기에 신경망 네트워크를 복잡한 구조로 만들 수 있다.(활성화함수가 linear가 아닌 x에 대한 이차식이라면 함수를 계속 합성할 경우 고차 다항식 형태가 되고 복잡한 구조를 가지게 된다.)
5) hidden layer의 벡터를 얻을 때는 앞의 layer 벡터에 대해 위의 연산(weight 곱하고 bias 더하기)을 수행했다.
그러나 output layer의 벡터를 얻을 때는 Softmax 함수를 사용한다.
Softmax 함수 사용하는 이유: 활성화함수를 그대로 적용하면 결과를 해석하기 힘들다.(ouput값이 가장 큰 것 선택)
그러므로 output의 값들의 합이 1이 되도록 개별 output node들마다 산출될 비율을 확률의 형태(수학적으로 확률값은 아니지만 확률의 모습을 가진다) 로 계산한다.

3. DNN의 프로세스 정리
1)input: 입력받은 자료를 벡터(matrix)로 변환해 input 값으로 들여온다.
2)hidden layer: 받은 input 벡터에 대해 W(weight) 벡터를 곱하고 b(bias) 벡터를 더하는 연산을 n번 반복해, 마지막 hidden layer 값을 얻는다.
3)output:
이 때 W,b벡터(파라미터 세타)가 결과의 정확도에 있어 매우 중요하다.
cost function을 통해 실제 값과 예측 값의 차이를 측정하고 이를 최소화해야 한다.
=> backpropagation 방법을 통해 W 벡터를 매우 효율적으로 학습한다!
(backpropagation은 딥러닝에서 매우 중요한 단계)
-고려대학교 수학과 오승상교수님의 강의 참고
'딥러닝' 카테고리의 다른 글
| [Easy! 딥러닝] Chapter 6. 배치 정규화와 레이어 정규화의 의미와 필요성 (0) | 2025.05.16 |
|---|---|
| [Easy! 딥러닝] Chapter6 앞부분까지 새롭게 배운 내용 (0) | 2025.05.15 |
| [DL Study] 4. Cost gradient descent (0) | 2025.04.29 |
| [DL Study] 2. Perceptron, MLP (0) | 2025.04.05 |
| [DL Study] 1. Introduction (0) | 2025.04.03 |